基于图像的缺陷检测的全卷积交叉尺度流
Fully Convolutional Cross-Scale-Flows for Image-based Defect Detection
摘要
在工业制造过程中,错误经常发生在不可预测的时间和未知的表现中。我们解决了自动缺陷检测的问题,而不需要缺陷部件的任何图像样本。Recent works对无缺陷图像数据的分布进行了建模,使用强统计先验或过于简化数据表示。相比之下,我们的方法处理细粒度表示结合了全局和同时灵活地估计密度。致为此,我们提出了一种新的全卷积交叉尺度联合处理多个数据的标准化流(CS流)不同比例尺的特征图。使用标准化流为输入样本分配有意义的可能性允许在图像级别进行高效的缺陷检测。此外,由于保留的空间布局规范化流是可解释的,这使得能够进行本地化图像中的缺陷区域。我们的工作在基准上开创了图像级缺陷检测的新局面磁砖缺陷和MVTec AD数据集显示15节课中有4节达到100%AUROC。
1.导言
在部件的工业生产过程中,缺陷随着时间的推移而发生。必须检测它们以确保安全标准和产品质量。自手动检查以来人类成本高昂,容易出错,可靠高效对自动缺陷检测的要求很高。在大多数情况下然而,在现实世界中,没有这样的例子的缺陷。此外,即使有一小部分已知的缺陷可用,新的和以前看不见的缺陷类型也会在不可预测的时间出现,这使得无法应用标准的分类方法。相反,不可避免的是,缺陷检测器只能从无缺陷的示例。这个问题通常被称为半监督异常检测(AD)、新颖性检测或一个类别分类。
这些术语描述了决定是否数据样本属于图1中给定集合X的类。我们的方法基于以下内容检测和定位缺陷从不同大小的输入图像中估计特征图的密度。我们联合处理多尺度特征图,使用一个在尺度之间具有交叉连接的完全卷积归一化流。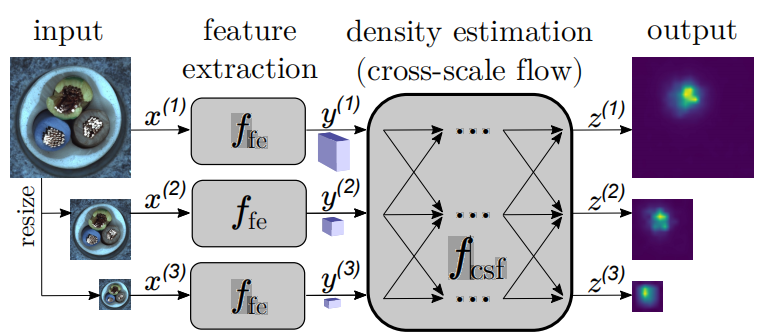
AD领域的大多数研究[14,37,32]都集中在具有高类内方差和高类间方差的图像数据集。缺陷检测中的设置不同:因为无缺陷的组件与其自身相似,对于这些缺陷,存在较小的类内方差和类间方差。因此,大多数AD方法都不合适用于缺陷检测。基于autoen编码器[42,12,6,15]或生成对抗网络的常见方法(GAN)[34,1,7]在这种设置下表现不佳,详见第2节。因此,最近的作品依赖于从模型中获得的图像特征的密度估计在ImageNet上进行预训练[9],例如ResNet[17]或Efficient Net[38]。然而,由于特征图的平均值[31]或强统计先验需要限制它们在密度估计中的灵活性[29, 8]. 为了缓解这些问题,我们提出了一种能够处理多尺度特征的标准化流(NF)如图1所示。NF是将训练集分布pX转换为具有预定义分布的潜在空间的生成模型pZ通过最大似然优化。与…对比其他生成模型,例如VAE[21]和GAN[16,4],NF中潜在空间向量的可能性为直接解释为输入数据的可能性,因为网络是双射映射的。因此,潜在的区域高似然空间表示正常示例而有缺陷的例子被投影到潜在变量中在学习分布之外。相反,injective自动编码器的映射可能会导致投影未经训练的异常到不确定的潜在空间区域,其可以与正常样本的区域重叠。
然而,将NF应用于图像以进行OOD检测如Kirichenko等人[22]所示,这并不简单。对于RGB数据,网络无法学习有用的分布,只关注局部像素相关性而不是语义。因此,我们对通过提供压缩语义信息的预训练特征导出器获得的特征图进行密度估计。我们的跨尺度流程(CS flow)同时处理图像在不同尺度下的传播特征它们通过NF并行运行,同时与每个NF相互作用其他。记住,关于在训练过程中,缺陷是未知的,我们的模型充分利用了训练中信息和相关性的全部潜力本地和全局上下文都可以精确地学习分布,以识别有缺陷的示例。除了身份-此外,全卷积架构还保留了允许可视化的空间布局图像上的缺陷区域。与使用密集连接的层,因此有许多参数[31],即使使用训练样本数量少。 我们将我们的贡献总结如下: •我们的新型跨尺度归一化流(CS flow)通过联合估计多尺度特征图上的可能性来检测缺陷。 •我们的方法保持图像结构,以获得可解释的潜在空间,实现精确的缺陷检测。 •我们在MVTec AD和磁砖缺陷的图像级缺陷检测方面设置了新的最先进技术数据集。 •代码可以在GitHub1上找到
2.相关工作
在下文中,我们回顾了在异常检测和归一化流作为我们的基础方法论。
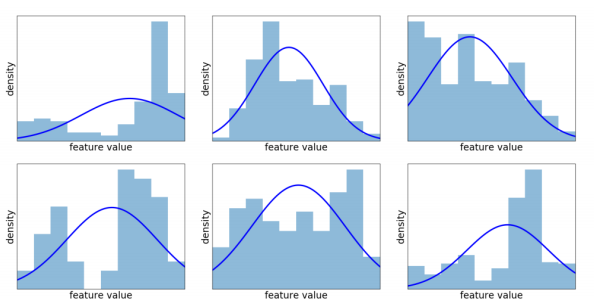
图2:用EfficientNet提取的MVTec AD图像不同特征的直方图[38]。每个直方图包含来自一个特征图的相同位置的值。蓝色这条线显示了最拟合的正态分布。假设特征分布正常,如[29,8]所做的那样,似乎不足以捕捉特征分布。
2.1. 异常检测
最先进的工作可以大致分为基于生成模型或预训练的方法网络。不属于以下任一情况的替代方法这些类别将单独描述。
2.1.1生成模型
许多异常检测方法都是基于生成的模型,如自动编码器[24,21,30]和GAN[16],其被优化以生成正常数据。这些方法通过生成能力的丧失来检测异常模型来重建它们。在最简单的情况下,输入并对自动编码器的重建进行了比较[42]。在这种情况下,高重建误差被解释为异常的指示器。Bergmann等人[6]取代了SSIM的常见l2错误可以更好地衡量视觉相似性。Gong等人[15]在防止自动编码器泛化的潜在空间异常数据。翟等人[41]将基于能源的模型和正则化自编码器来模拟数据分布。黄等人使用去噪自动编码器al.[12]通过让自动编码器学习恢复转换后的图像。
与自动编码器的解码部分类似,GAN的生成器用于异常检测。施莱格尔等人[34]提出在训练GAN后学习逆生成器,同时利用两者进行重建和错误考虑。自动编码器和GAN由Akcay等人提出[1]。他们应用自动编码器直接作为GAN的生成器,以确保仅生成正常数据。
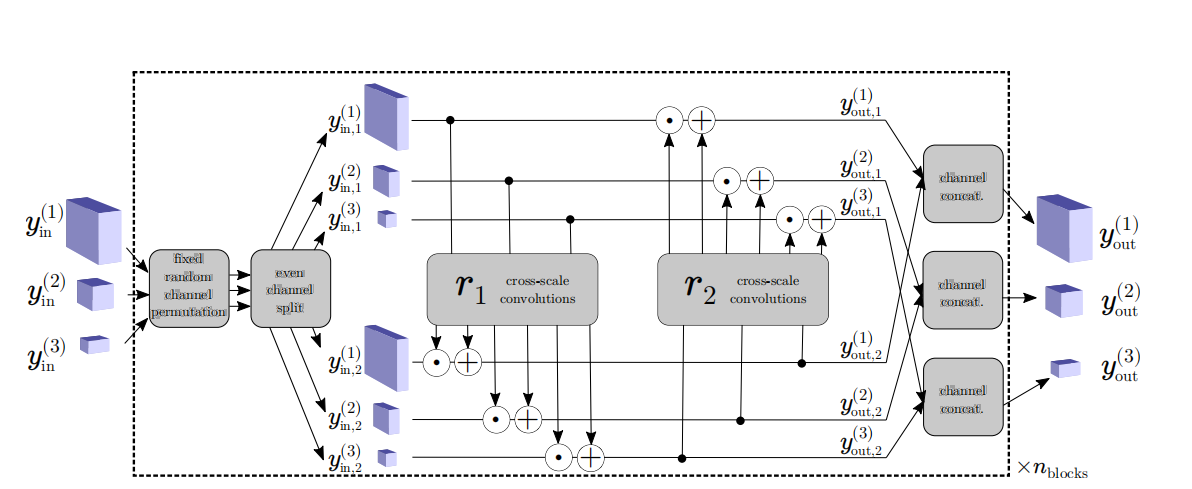
图3。归一化流中一个块的架构:经过固定的随机置换后,每个输入张量被分成两部分在信道维度上,每个系综用于估计变换相应对应物的尺度和偏移参数。符号和⊕分别表示元素乘法和加法
如第4.3节所示,自动编码器和GAN在缺陷检测任务中表现不佳。由于不同类型具有个体大小、形状和结构的异常由于重建误差的特征不一致,它们并不广泛适用。例如,具有以下结构的高频通常不能准确地表示和重建,小的缺陷区域会导致较小的误差。
2.1.2基于预训练网络的方法
许多方法不是直接处理图像对预训练网络的特征进行缺陷检测。在大规模数据库(如ImageNet)上进行预训练,可以确保提取出预期的通用特征在存在缺陷的情况下有所不同。通过这种方式,考虑了无法从中学习到的描述特征无缺陷数据,因为它们不一定出现在通常在特征空间中检测缺陷使用传统的统计方法。
Andrews等人[2]将一类支持向量机拟合到特征分布中。Rippel等人[29]模型特征为单峰高斯分布,并利用马氏距离作为评分函数。这个Defard等人[8]进一步改进了该方法,将其应用于利用不同特征图的图像补丁语义层面。然而,这些方法仅限于在许多情况下不合适的正态分布如图2所示。相比之下,我们不假设任何预定义的特征分布,但通过最大似然估计(MLE)学习真实分布。假设特征空间内的距离在语义上是可表达的,到最近邻的距离被用作[27]中的异常评分。唯一基于深度学习的图像Rudolph等人[31]提出的特征密度估计方法,与我们的工作最具可比性的,也是基于关于流量的正常化。然而,它们不处理全尺寸的特征图,而是在应用平均池后处理向量。因此,重要的上下文和位置信息丢失了。作者通过在网络中传递每个图像的64次不同旋转来部分弥补这一弱点,然而,这大大增加了计算复杂性。相比之下,我们的方法利用全尺寸特征的细粒度信息地图,只需要一次通过,性能优于DifferNet[31]在几乎所有实验中都有很大的优势。
2.1.3其他方法
除了生成模型和预训练模型外,还有其他方法来执行异常检测。Lizner-ski等人[26]提出了一种可学习的超球面分类器,该分类器使用样本异常暴露作为异常替代。同一图像增强的对比学习是Tack等人[37]通过定义分布内和分布外变换来使用。相比之下,Golan和El Yaniv[14]增强了图像以对特定的转换进行分类,假设这在以下情况下不那么清楚异常情况与正常数据一样。
2.2. 标准化流程
归一化流(NF)[28]是一种生成模型将数据转换为易于处理的分布。与传统的神经网络不同,它们的映射是双射的允许他们在两个方向上进行训练和评估[39]。正向传递将数据投影到潜在空间中,以计算给定预定义潜在空间的数据的后期精确似然性分布。相反,从预定义的 分布可以映射回原始空间生成数据。双射性和双向执行是通过使用可逆仿射变换来确保。那里是不同类型的归一化流,它们在实现仿射变换的体系结构-有效地启用前进或后退方向。仿射块是通过学习固定或自回归来实现的转变。一种流行的自回归流是MADE(Germain等人[13])。密度计算基于在这种情况下,贝叶斯链规则是有效的。然而,采样成本很高。相反,逆自回归流动(Kingma等人[20])通常在采样时是有效的,但在计算可能性方面并非如此。Real NVP[11]是一种逆自回归流的变体,它将这两个过程简化为在两个方向上都要高效。我们增强了Real NVP在可以相互作用的多个尺度上操作。这通过全面引入NF来利用NF进行缺陷检测卷积跨尺度流,其架构在第3.1节中有详细说明。
归一化流已成功用于非图像数据的异常检测[33,35,10]。对于图像数据,出现了网络主要集中在本地的问题不考虑语义的像素相关性。最近的研究[31,22]发现,在处理图像特征时,语义信息比完整信息更容易被捕获图像。与[22]相反,我们使用来自多个缩放并避免使用完全连接的层与挤压层2通过这种方式,我们的潜在空间得以保留空间排列,因此能够实现精确的缺陷本地化。此外,我们减少了参数的数量,使我们能够处理高维特征使用很少的数据样本进行地图和训练。
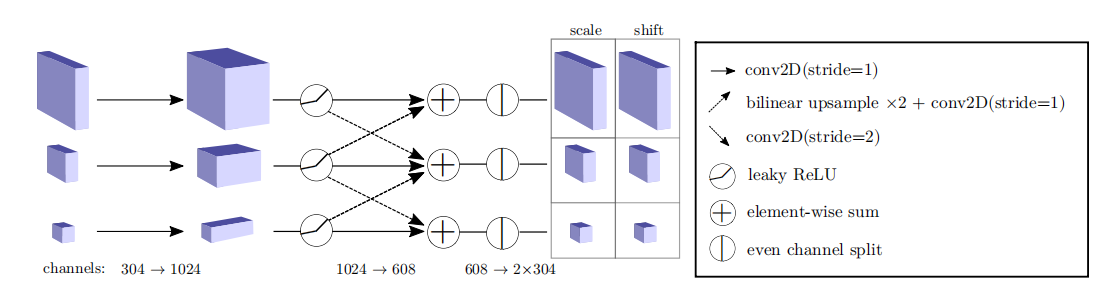
图4。耦合块内部网络的架构。卷积在两个级别上执行,在第二个级别上进行标尺之间的交叉连接。特征图大小调整是通过上采样和跨步卷积实现的。聚合通过求和来实现。输出在通道维度上进行分割,以获得缩放和偏移参数。
3.方法
为了检测图像中的缺陷,我们首先学习统计无缺陷图像
具有相同的维度
我们使用
3.1. 跨尺度流
我们通过新颖的跨尺度流程扩展了传统的归一化流程,以实现对图像的有效缺陷检测。它处理彼此交互的不同大小的特征映射。通过这种方式,尺度之间的信息被共享,以获得
跨尺度流是一系列所谓的耦合块,每个块都执行仿射变换。作为耦合块框架架构的基础,我们选择了 RealNVP [11]。一个区块的详细结构
跟
我们对栅尺组件进行软夹紧
这通过将值限制为区间来防止极端缩放分量
3.2. 学习目标
在训练期间,我们希望跨尺度流
我们优化了对数似然,因为它是等效的,并且对于密度更方便
跟
3.3. 本地化
在以前的工作 [31] 中,归一化流的潜在空间只被用于
与定义整个图像的异常分数类似,我们为每个局部位置定义一个异常分数
4. 实验
4.1. 数据集
我们在各种真实的缺陷检测场景中评估了我们的方法,以证明我们的贡献的优势和优于以前的方法。为此,我们测量了具有挑战性和多样化的 MVTec AD [5] 和磁性瓦片缺陷 (MTD) [18] 数据集的性能。
MVTec AD 包括 10 个对象和 5 个纹理类别,总共有 3629 个无缺陷训练和 1725 个测试图像。每个类包含 60 到 320 张高分辨率图像,范围从
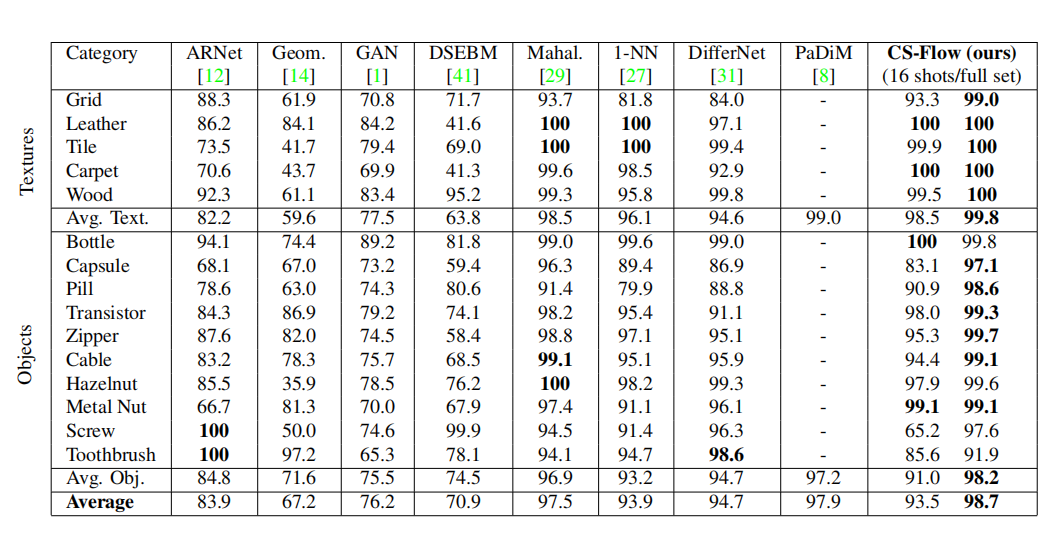
表 1.ROC 下的面积
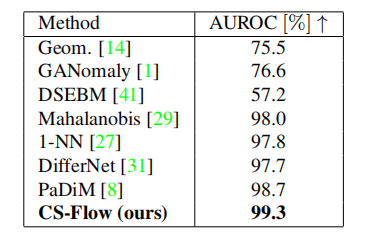
表 2.用于检测 MTD 异常的 ROC 下面积(以 % 为单位)。
作为常见的选择,我们还在 MTD 数据集上进行评估,其中包括磁性瓦片的灰度图像有缺陷和无缺陷。由于磁势不相等,所包含的缺陷(例如破损和气孔)可能会导致发动机出现问题。值得注意的是,由于照明和其他非缺陷特性的差异,该数据集在无缺陷示例中显示出很大的差异。按照 [31],我们使用所有 392 张缺陷图像和 952 张无缺陷图像中的五分之一进行测试,并使用剩余的无缺陷数据进行训练。
4.2. 实现细节
我们利用 EfficientNet-B5 [38] 第 36 层的输出作为所有实验的特征提取器,因为它提供的特征图在特征语义水平和空间分辨率之间具有良好的平衡。特征提取器在 ImageNet 上进行预训练后,在训练期间保持固定 [9]。对于 MVTec AD,我们使用
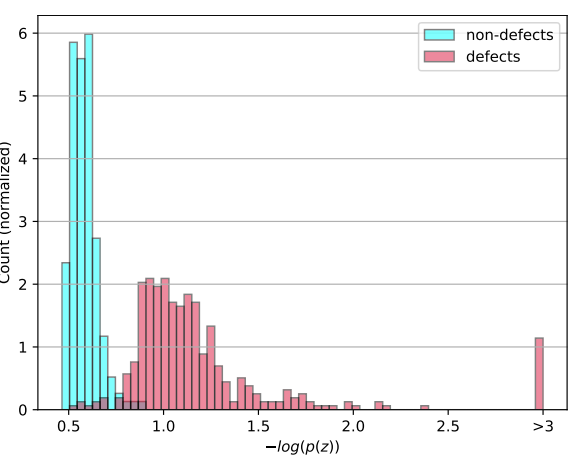
图 5.MTD 测试图像的负对数似然分布为归一化直方图。根据此标准,有缺陷的样品几乎与无缺陷的样品完全分开。请注意,为清楚起见,最右侧的条形汇总了 3 以上的所有分数。
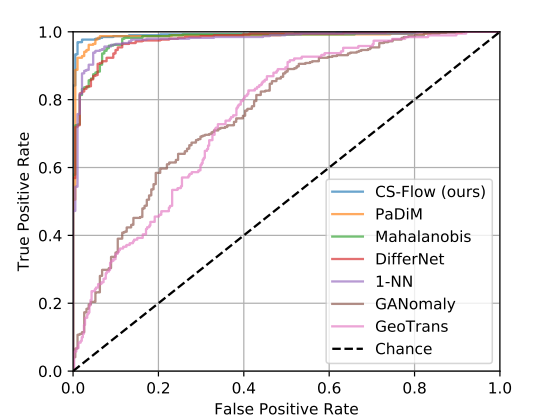
图 6.MTD 上不同方法的缺陷检测性能比较。图形是各个方法的 ROC 曲线。最好用彩色观看。
4.3. 检测
为了测量和比较我们模型的缺陷检测性能,我们遵循 [31] 并计算相应测试集上图像级别的 ROC 下面积 (AUROC)。ROC(接受者操作特征)曲线将真阳性率与参数(在我们的例子中为阈值)的假阳性率相关联
我们还设定了新的技术水平
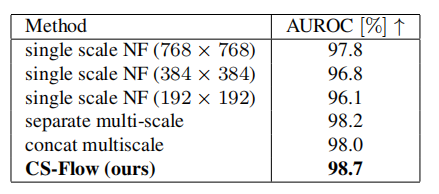
表3.MVTec AD 的消融研究,关于秤使用的不同策略。

表 4.不同数量的耦合块的 MVTec AD 的消融研究。
4.4. 本地化
虽然我们方法的目标是在图像级别检测缺陷,但由于其全局和局部特征保留的性质,它也可以用于定位图像中的缺陷区域。在本节中,我们将学习本地化,如 第 3.3 节所述。我们的目标是为操作员提供快速的视觉反馈。图 7 显示了最高规模输出的可视化
4.5. 消融研究
为了量化我们模型的各个设计决策的影响,我们报告了在改变我们方法的超参数时获得的结果。表 3 显示了这些实验的结果。我们衡量多尺度方法对缺陷检测性能的影响。为此,我们一次从三个尺度之一的特征图上训练模型(表示为单尺度 NF)。结果证实,单个量表的特征在区分有缺陷的样本和非有缺陷的样本方面较弱。此外,我们通过添加来自每个尺度的网络提供的对数似然(表示为单独的多尺度)来设置另一个基线。与单一尺度模型的单个性能相比,AUROC 的增加表明,不同尺度的特征可以很好地互补以获得更稳健的分数。尽管如此,这种方法是
在另一个实验中,我们研究了耦合块数量的影响。表 4 中的结果表明,性能随着耦合模块数量的增加而提高,最高可达
为了在正常数据中具有更多类内方差的设置上测试我们的模型,我们同时对所有 15 类 MVTec AD 作为正常数据进行了额外的实验训练。平均检测 AUROC 为
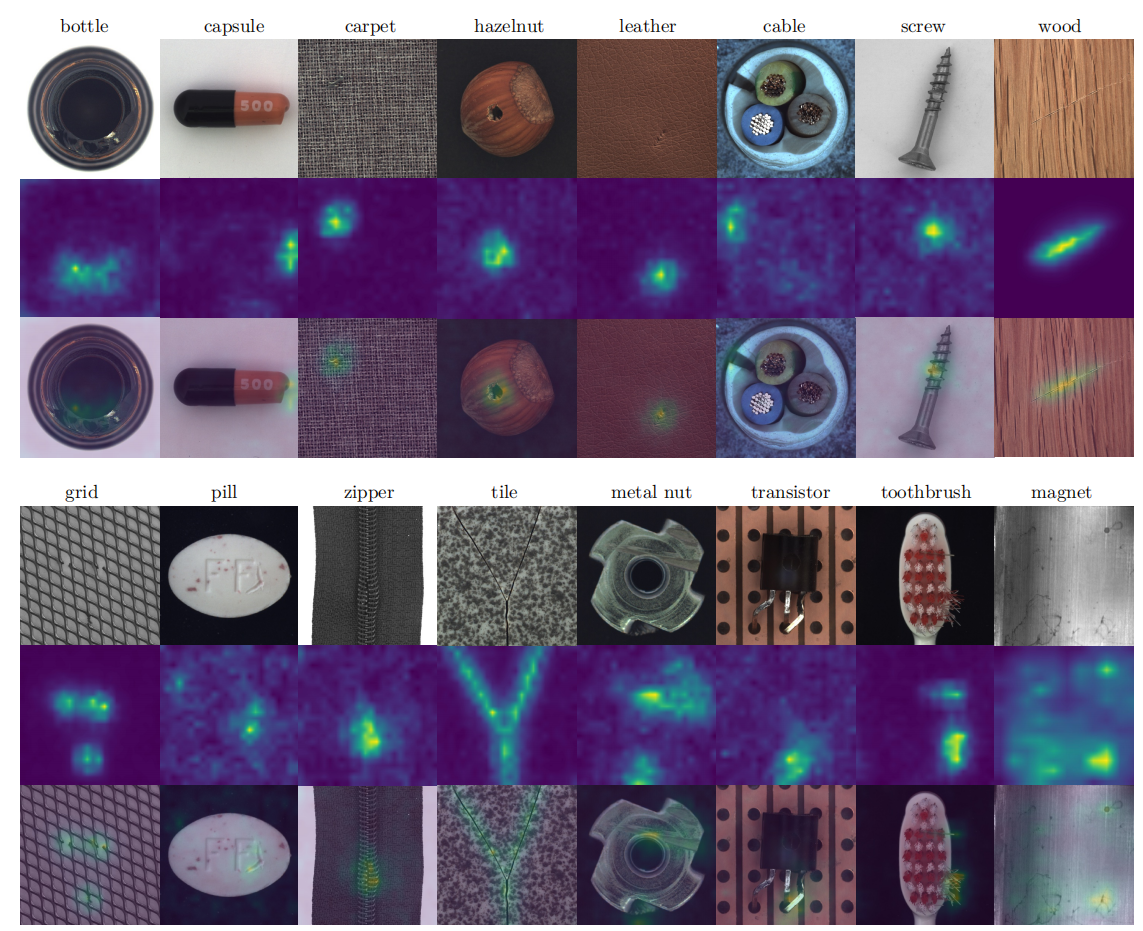
图 7.每个 MVTec AD 和 MTD 类别一个缺陷示例的缺陷定位。各行从上到下分别显示原始图像、位置和两个图像的叠加层。定位图以最高比例显示沿网络输出的通道维度的平方和。
5. 总结
我们提出了一种半监督方法,使用归一化流有效地检测和定位不同尺度的特征张量上的缺陷。我们通过在归一化流程中集成交叉卷积块来利用多尺度特征图内部和之间的上下文来分配可能性并将不太可能的样本检测为缺陷。这解决了以前方法的弱点,这些弱点由于过于简化的数据表示的限制或有限的分布模型而难以实现,并使我们的方法能够在 MVTec AD 和 MTD 上设置最先进的性能。将来,这个概念可以被改进为视频异常检测[40, 25]。 这项工作得到了德国联邦教育和研究部 (BMBF) 在 LeibnizKILabor 项目(资助号 01DD20003)、数字创新中心 (ZDIN) 和德国研究基金会 (DFG) 的支持,根据德国卓越战略在卓越集群 PhoenixD (EXC 2122)。
引用
[1]Samet Akcay、Amir Atapour-Abarghouei 和 Toby P. Breckon。Ganomaly:通过对抗性训练进行半监督异常检测。在 Computer Vision-ACCV 2018 中,第 622-637 页,Cham,2019 年。施普林格国际出版社。
[5] 保罗·伯格曼、迈克尔·福瑟、大卫·萨特莱格和卡斯滕·斯特格。Mvtec ad-用于无监督异常检测的综合真实数据集。在 IEEE 计算机视觉和模式识别会议论文集,第 9592-9600 页,2019 年。5, 6
[6] 保罗·伯格曼、辛迪·勒维、迈克尔·福瑟、大卫·萨特莱格和 C. 斯特格。通过将结构相似性应用于自动编码器来改进无监督缺陷分割。在 VISIGRAPP,2019 年。1, 2
[7] Haoqing Cheng, Heng Liu, Fei Gao, 和 Zhuo Chen.Adgan:一种基于 gan 的可扩展架构,用于图像异常检测。2020 年 IEEE 第 4 届信息技术、网络、电子和自动化控制会议 (ITNEC),第 1 卷,第 987-993 页。IEEE,2020 年。1
[8] 托马斯·德法尔、亚历山大·塞特科夫、安杰利克·洛施和罗马里克·奥迪吉尔。Padim:用于异常检测和定位的补丁分布建模框架。在模式识别中,ICPR 国际研讨会和挑战,2021 年。1, 2, 3, 6, 7, 8
[9] 邓佳, 魏东, 理查德·索彻, 李李佳, 李凯, 李飞飞.Imagenet:大规模分层图像数据库。2009 年 IEEE 计算机视觉和模式识别会议,第 248-255 页。IEEE,2009 年。1, 6
[10] Madson LD Dias, César Lincoln C Mattos, Ticiana LC da Silva, José Antônio F de Macedo, and Wellington CP Silva.使用规范化流对轨迹数据进行异常检测。arXiv 预印本 arXiv:2004.05958,2020 年。4
[11] Laurent Dinh、Jascha Sohl-Dickstein 和 Samy Bengio。使用真实 nvp 进行密度估计。国际法律评论,2017 年,2016 年。4, 5
[12] 叶飞, 黄朝琴, 曹金坤, 李茂森, 张雅, 卢策武.用于异常检测的属性恢复框架。IEEE 多媒体汇刊,2020 年。1, 2, 6
[13] 马蒂厄·日耳曼、卡罗尔·格雷戈尔、伊恩·默里和雨果·拉罗谢尔。制作:用于分布估计的掩码自动编码器。在机器学习国际会议中,页面
- 1 https://github.com/marco-rudolph/cs-flow
- 2Squeeze layers 重塑张量,例如通过将 4 个相邻像素的通道聚合为一个具有四倍通道号的像素。
- 3为了提高可读性,在以下z没有任何索引表示一个向量,该向量是扁平化张量的串联[z(1),…,z(s)].