CFA:基于耦合超球体的特征适应用于面向目标的异常定位
CFA: Coupled-hypersphere-based Feature Adaptation for Target-Oriented Anomaly Localization
摘要
长期以来,异常定位在工业中得到了广泛应用。以前的研究集中在近似正常特征的分布,而没有针对目标数据集进行适配。然而,异常定位需要精确区分正常和异常特征,缺乏适应可能导致异常特征的正常性被高估。因此,我们提出了基于耦合超球体的特征适应(CFA),通过适应目标数据集的特征来实现精细的异常定位。CFA包括:(1) 一个可学习的补丁描述符,学习并嵌入面向目标的特征,以及(2) 一个独立于目标数据集大小的可扩展内存库。此外,CFA采用迁移学习来增加正常特征密度,从而通过将补丁描述符和内存库应用于预训练的CNN,清楚地区分异常特征。该方法在MVTec AD基准测试的异常检测中提供了99.5%的AUROC评分,在异常定位中提供了98.5%的AUROC评分。此外,本文指出了预训练CNN的偏置特征的负面影响,并强调了适应目标数据集的重要性。
1. 引言
异常检测是一项众所周知的计算机视觉任务,用于检测给定图像中的异常特征。人类视觉系统 (HVS) 可以轻松识别图像中的意外模式,即异常,无论特征复杂程度如何。随着 CNN 的快速发展,机器视觉系统可以通过学习抽象特征来识别异常。除了图像级异常检测外,异常定位,即像素级异常检测也得到了积极研究。异常定位提供了一个热图,指示异常值的位置以及异常值的存在与否。请注意,热图可以作为解释异常原因的起点。
同时,异常定位算法无法考虑学习中所有可能的异常值。换句话说,他们无法构建包含所有异常值的数据集。因此,通过学习正常样本的分布来区分异常样本一直是主流方法。例如,基于无监督学习的方法(如[3,19]利用了仅使用正常特征训练的生成器无法成功重建异常特征的特性。基于自我监督学习的方法,例如[11,21,23]合成噪声并将其用作学习中的异常样本。最近[4,5,16]使用带有大型数据集(如 ImageNet)的预训练 CNN 设计内存库[6]并实现了最先进的 (SOTA) 性能。这种基于内存库的方法从预先训练的 CNN 中提取足够广义的特征,而无需学习目标数据集,然后将它们存储到内存库中。最后,它通过将输入特征与记忆特征进行匹配来确定输入样本是否异常。
但是,工业映像通常具有与 ImageNet 不同的分布。因此,预训练的 CNN 仅从新的工业图像中提取未拟合的特征。这可能是异常定位中的一个致命问题,需要精确区分正常特征和异常特征。[16]指出了预训练 CNN 提取有偏差特征引起的不匹配问题。它只使用了偏差相对较小的中级特征,但并没有从根本上解决失配问题。
异常定位的性能取决于内存条的大小。传统方法将目标数据集的法向特征尽可能多地存储在内存库中,以容纳未拟合的特征,即理解法向特征的分布。因此,内存库的大小与目标数据集的大小成比例确定。然而,内存库中的大量未拟合特征可能会导致异常特征被高估正常性的风险。此外,大容量内存库增加了推理时间。
为了获得判别性正常特征,我们提出了一种新的方法,通过将迁移学习应用于预先训练的 CNN 来产生具有减少偏差的目标导向特征。首先,我们定义了一个基于软边界回归的新型损失函数,该函数搜索具有最小半径的超球体,以密集地聚集正常特征。所提出的损失函数通过利用形成耦合超球体的几个记忆特征,帮助可学习的补丁描述符提取判别性特征。接下来,为了减少推理时间,我们提出了一个可扩展的内存库。由于可扩展的内存库与目标数据集的大小无关,它不仅减轻了异常特征被高估正常性的风险,而且实现了空间复杂性的效率。因此,所提出的方法可以通过将适当的目标导向特征提取到目标数据集中,并构建一个缩小的内存库来具有核心法线特征,从而有效地定位异常。
我们使用 MVTec AD 基准测试评估了所提出的方法[1],这是一种用于视觉检查的常用工业图像数据集。所提出的方法在异常检测性能指标,即图像级 AUROC (I-AUROC) 方面表现出 99.5% 的性能,在异常定位性能指标,即像素级 AUROC (P-AUROC) 方面,实现了 98.5% 的 SOTA 性能。特别值得注意的是,所提出的方法提供了比传统方法更好的性能,同时减少了约 99.9% 的内存库的激活[7].
贡献。本文的贡献总结如下:
1) 我们发现了来自预训练 CNN 的偏向特征对异常定位的负面影响,并提出了对目标数据集的调整作为解决方案。
2) 我们提出了一种通过度量学习获取判别特征的新方法,并通过实验验证这些特征能够实现非常复杂的异常定位。
3) 通过特征适应独立于目标数据集的大小进行压缩的内存库,尽管其容量显着降低,但仍实现了 SOTA 性能。
2. 相关工作
通常,获取异常样本需要大量成本,并且无法考虑所有类型的异常。因此,基于内存库的方法应运而生,该方法通过使用预训练的CNN推断目标数据集来获取正常特征。文献[4]从特征图中获取正常特征,并将其存储在内存库中。在测试时,它通过计算内存库中的正常特征与测试样本中的补丁特征之间的欧氏距离来计算异常分数。文献[5]通过在特征图的每个位置对正常分布建模来定义内存库。为了进一步考虑特征间的相关性,该方法采用了马氏距离度量来计算异常分数。文献[16]仅使用中层特征图来减轻特征偏差,并通过考虑每个正常特征的邻居特征来最大化正常信息。此外,该方法提出了贪婪核心集子采样,以减轻内存库的时间/空间复杂度。然而,上述方法的共同点在于它们在没有适应的情况下使用了基于大型数据集的偏置特征。此外,内存库的大小仍然与目标数据集的大小成正比,存在内存库不能调整到任意大小的问题。
3. 提出的方法
这篇文章提出了所谓的CFA,采用对目标数据集执行迁移学习来缓解预训练CNN的偏差问题。CFA的补丁描述符学习从目标数据集的正常样本中获得的补丁特征,使其在记忆特征周围具有高密度。因此,CFA解决了使用预训练CNN时异常特征的正常性被高估的问题。
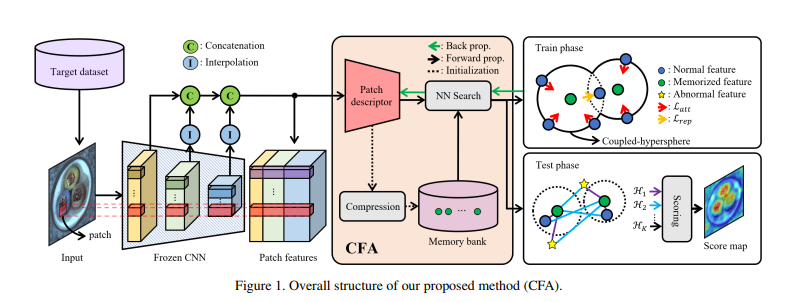
如图1所示,CFA通过使用基于大型数据集(即带有偏差的CNN)预训练的CNN来推断目标数据集的样本,获取不同尺度的特征图。由于在CNN的每个深度处采样的特征图具有不同的空间分辨率,它们被插值为相同分辨率,然后按照[5]中的方法进行连接。最终,生成补丁特征
同时,所有从仅包含正常样本的训练集中获得的初始面向目标的特征根据特定的建模过程存储在内存库
本文的结构如下:3.1节定义了
3.1 基于耦合超球体的特征适应
本节介绍如何通过基于记忆库的迁移学习来学习附加在预训练CNN上的
为了获得能够清晰检测异常特征的特征空间,我们提取聚类的正态特征,使
其中,超参数K为与
然而,同时属于多个超球的模糊
其中超参数
最终,CFA通过结合公式(1)和(2)来优化
如果与
3.2 内存库压缩
迁移学习和记忆库压缩
在基于压缩与特征适应(CFA)方法的迁移学习中,有效的记忆库对适应目标数据集至关重要。然而,如表 1 所示,以往的方法 [4, 5, 16] 显示,记忆库的建模过程或空间复杂度通常随着目标数据集大小(
记忆库压缩过程

算法 1 描述了记忆库的压缩过程。首先,通过对训练集
一旦建立了
对于每个正常样本
使用
对所有训练集中的正常样本重复这一过程
更新和复杂度
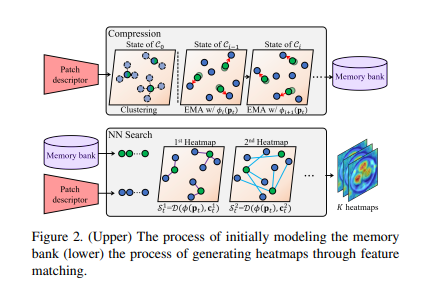
图 2 的上半部分展示了如何为目标数据集中的每个样本更新记忆特征。尽管通过
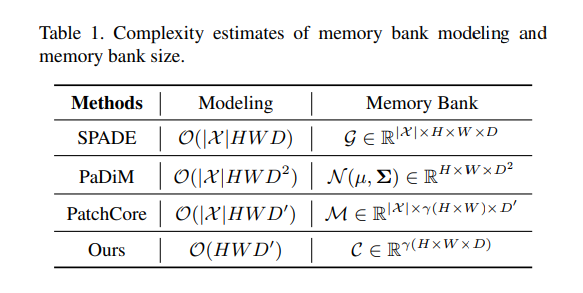
由于算法 1 在每个状态下都会更新记忆库
3.3 得分函数
在3.1节,计算了
然而,由于正常特征是连续分布的,簇之间的边界并不清晰。因此,使用这种简单的异常评分很难准确区分异常特征。具体来说,可能不确定哪些记忆特征会匹配
最后,在 CFA 的测试阶段,异常评分图是异常定位的最终输出,它是从热图中获得的。注意,这些热图是从简单的异常评分生成的,如图 2 下半部分所示。简而言之,生成并重新排列第
总之,CFA 使用提出的补丁描述符和记忆库进行目标导向的异常定位转移学习。然后,CFA 从任务导向的特征生成热图,并从中计算精细的异常评分。因此,CFA 解决了由预训练 CNN 的偏差特征导致的异常特征正常性被高估的问题。
4. 实验
本节展示了各种实验结果,以评估CFA在异常检测和定位方面的性能。所有实验都在MVTec AD基准测试数据集上进行,这是异常定位领域中最著名的数据集。为了验证所提方法的鲁棒性,我们还展示了在随机旋转和裁剪的MVTec AD数据集(称为RD-MVTec AD数据集)上的性能。作为评估指标,我们采用了受试者工作特征曲线下面积(AUROC),并以异常检测(I-AUROC)和定位(P-AUROC)两个方面评估所提方法的性能。在一些实验中,我们使用了每区域重叠曲线下面积(P-AUPRO)[2],它可以更精确地评估异常定位。
4.1 实验设置
本节描述了本文实验的配置。所有实验中使用的CNN均经过ImageNet预训练。为了在预训练的CNN上获取多尺度特征,我们从中间层提取对应于
在实验中使用的MVTec AD数据集是一个由5354个工业样本组成的最大数据集,其中1725个是测试样本。它分为15个子类,我们对每个类别分别进行迁移学习。对于预处理,数据集的每个样本都被调整为256×256大小,并被中心裁剪到224×224。此外,我们使用RD-MVTec AD数据集来进一步考虑更难检测异常的未对齐样本。RD-MVTec AD数据集的每个样本在±10°范围内随机旋转。经过随机旋转后,每个样本调整为256×256大小,然后随机裁剪到224×224。
4.2 定量结果
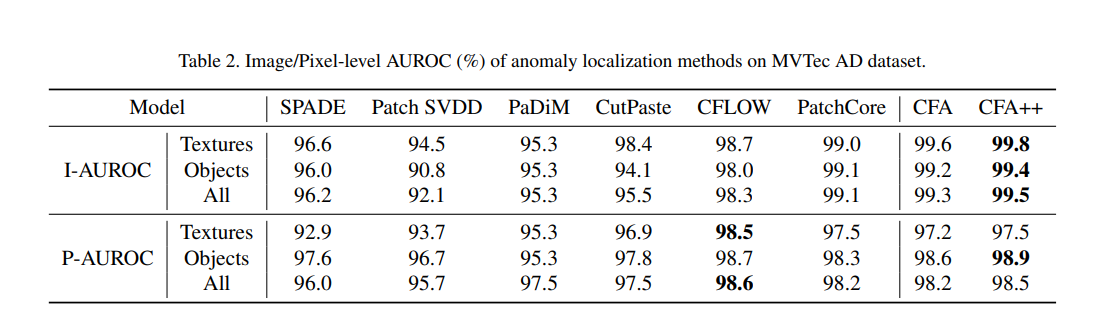
本节研究了 CFA 的定量性能。表 2 显示了 CFA 在 MVTec AD 数据集上的 I-AUROC 和 P-AUROC 结果,使用的是预训练的 WRN50-2 模型,该模型在 ImageNet 上进行过训练。在这里,CFA++ 指的是在使用裁剪图像和仅使用调整大小样本时对结果进行集成的情况。该方法在图像级异常检测性能的 I-AUROC 评估中,提供了当前最佳(SOTA)的表现,无论是在纹理类别还是物体类别上。例如,CFA++ 的 I-AUROC 比至今为止表现最佳的 PatchCore [16] 高出 0.4%。在像素级异常定位的评价指标 P-AUROC 方面,尽管该方法在所有类别中相比 CFLOW [8] 略逊一筹,但仍在物体类别中实现了 SOTA 性能。尽管如此,传统方法通常在异常检测和定位中只能在其中一种场景下表现突出,而本方法在这两种场景中都能保证出色的表现。此外,尽管使用的记忆库在空间复杂度上较 SPADE、PaDiM 和 PatchCore 更小,但该方法通过特征适应仍实现了卓越的性能。
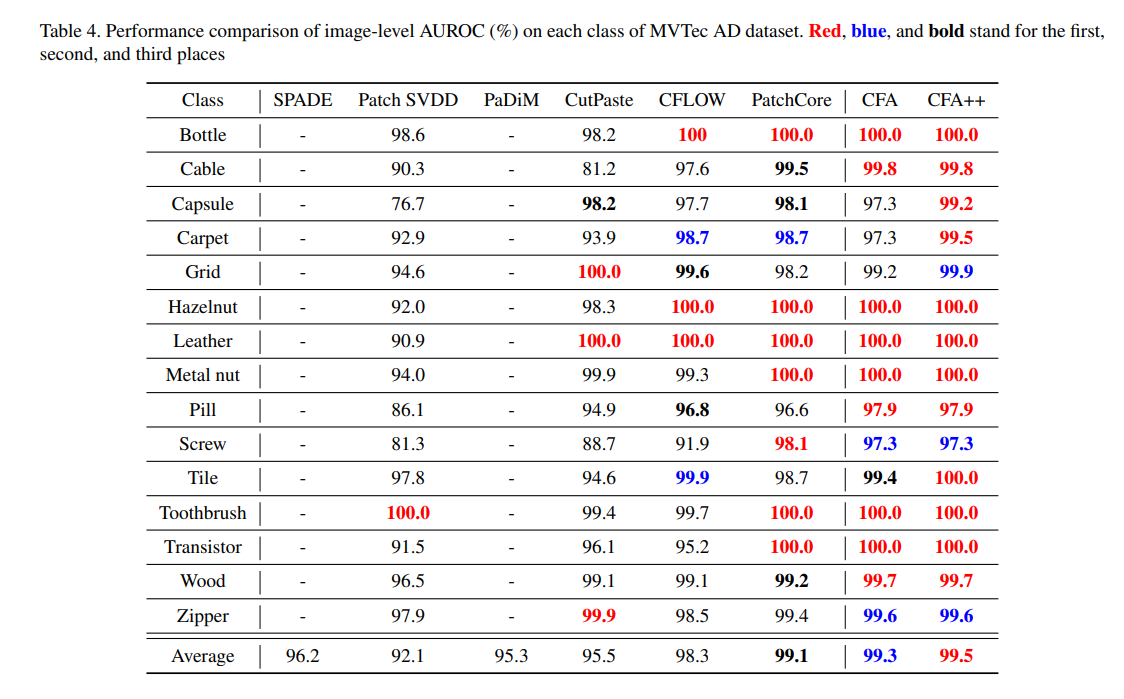
为了更清楚地展示该方法的性能提升效果,我们在表 4 中展示了每种架构的性能。可以发现,CFA++ 在大多数类别中提供了最高的性能。特别是,CFA 和 CFA++ 的最差性能仅为 97.3%,远高于大多数其他技术。这种趋势表明,由于提出的特征适应效应,CFA 在各种类别上具有了广泛的性能。
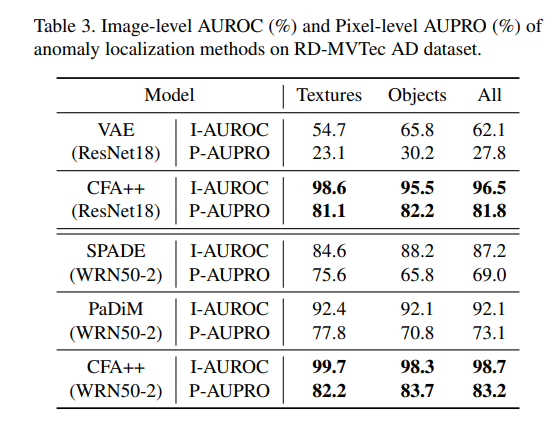
表 3 显示了 CFA 在 RD-MVTec AD 数据集上的性能。RD-MVTec AD 数据集包含与 MVTec AD 数据集相同的样本,但这些样本没有对齐。因此,该数据集的性能通常低于 MVTec AD 数据集。例如,与表 3 相比,SPADE 的 I-AUROC 下降了 9%。这表明 SPADE 对野生数据集非常脆弱。另一方面,即使在未对齐的样本中,CFA++ 的 I-AUROC 也仅显示了 0.8% 的轻微性能降级,这表明该方法可以像 HVS 一样稳健地区分正常特征。此外,与 SPADE 和 PaDiM 相比,CFA++ 分别显示了 11.5% 和 6.6% 更高的 I-AUROC 分数。在评估精细检测的 P-AUPRO 指标中也观察到了类似的趋势。例如,CFA++ 的 P-AUPRO 分数比 PaDiM 高出 10.1%。
4.3 消融研究
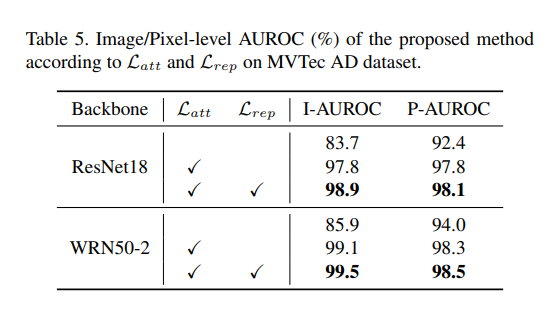
表 5 展示了特征适应对异常定位的影响。首先,考虑仅使用预训练 CNN 的偏差特征的情况。由于偏差特征的存在,非适应的预训练 CNN 尽管从大型数据集中获取了丰富的特征,但表现较差。这是因为正常特征的正常性由于偏差特征被低估,负面影响了异常定位。
此时,当仅使用
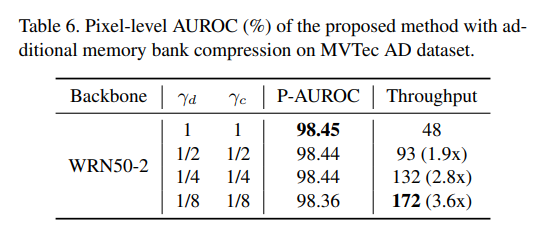
表 6 显示了当通过额外使用特征维度降低比例
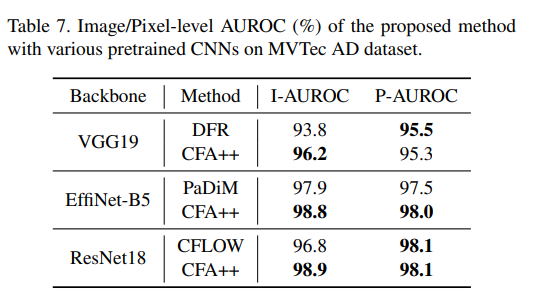
表 7 展示了根据预训练 CNN 的异常检测和定位性能。在这里,CFA 与前述方法 [5, 8, 17] 在 VGG19 [20]、EffiNet-B5 [22] 和 ResNet18 [10] 上进行了比较,这些模型是目前最常用于异常定位的模型。CFA 的 I-AUROC 分数分别比这三种预训练 CNN 高出 2.4%、0.9% 和 2.1%。因此,表 7 支持了所提方法的通用性。
4.4 定性结果
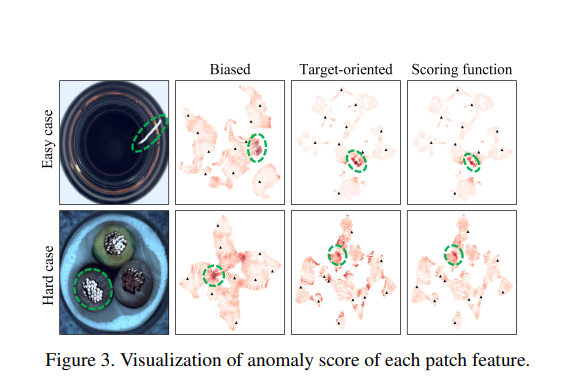
图 3 显示了根据特征适应和评分函数每个样本的补丁特征的异常分数。在这里,红色表示异常分数,虚线圆圈表示异常特征的区域,三角形表示记忆特征。当在适应之前使用偏向大型数据集的特征时,正常特征的正常性被低估,其分数与异常特征相似(见图 3 的第二列)。由于分数上的边界模糊,很难区分这两个特征。这会导致异常特征无法被精确区分的负面效果。
另一方面,当使用特征适应后的目标导向特征时,它们被很好地聚类。因此,易于处理的正常特征和异常特征可以明确地区分(见图 3 的第三列)。然而,仅凭聚类仍然不能准确地评分那些不确定的异常特征。在提出的评分函数中,通过考虑确定性来确定异常分数,因此即使是困难案例中的异常特征也能被精确区分,如图 3 的最后一列所示。结果是,所提方法的每一步有效地提高了异常定位性能。
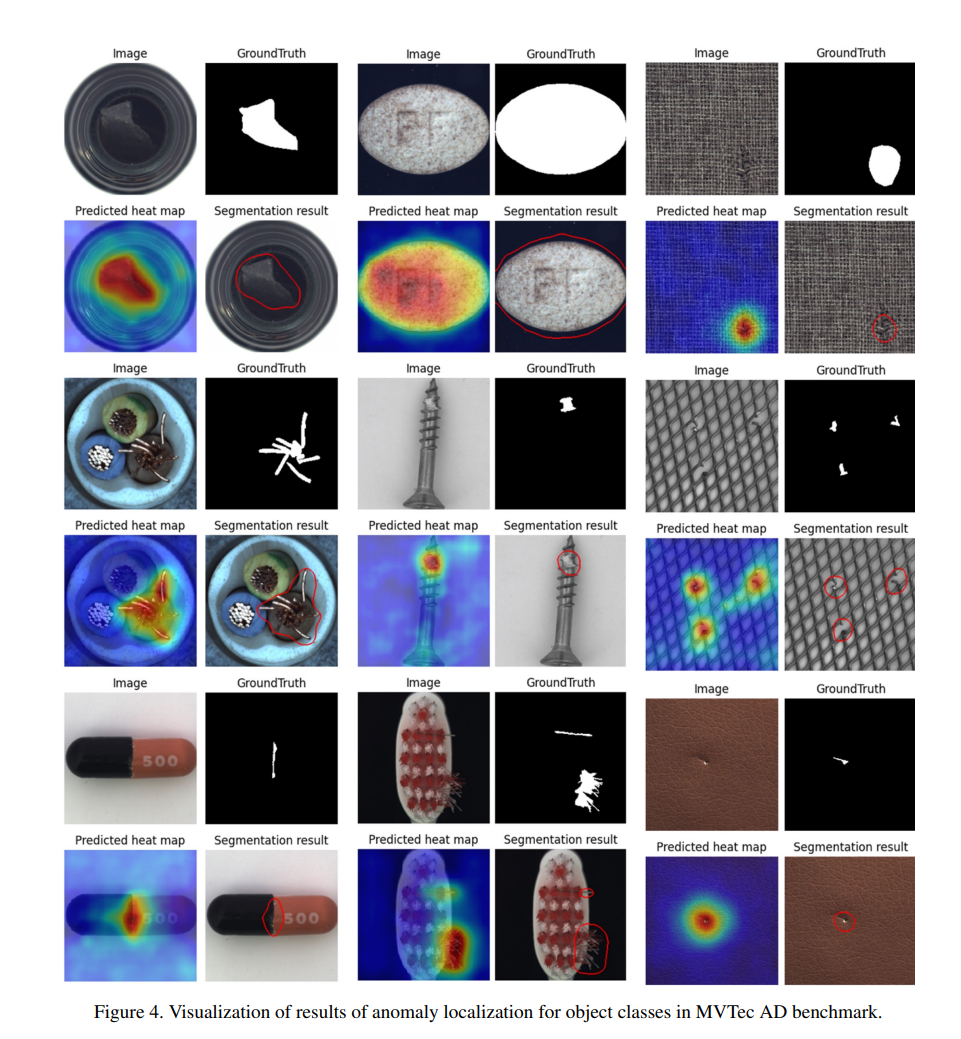
接下来,图 4 显示了异常定位的结果,指示异常区域。通过 CFA 获得的异常分数图被插值以具有输入样本的空间分辨率,并用
5. 结论
在本文中,我们指出了在异常定位中使用预训练 CNN 时产生的偏差问题,这主要发生在使用工业图像的情况下。为了解决这个问题,我们提出了基于耦合超球体的特征适应(CFA)方法,以获得面向目标的特征。CFA 由一个可学习的补丁描述符和一个存储记忆特征的记忆库组成。通过转移学习和补丁描述符与预定记忆库的特征适应,CFA 实现了成功的面向目标的异常定位。CFA 在 MVTec AD 基准数据集上表现出最先进的性能,MVTec AD 是由工业图像组成的最具代表性的数据集。然后,通过大量实验从定性和定量两个方面检查了特征适应对目标数据集的有效性。
6.References
[1] Paul Bergmann, Michael Fauser, David Sattlegger, and Carsten Steger. Mvtec ad–a comprehensive real-world dataset for unsupervised anomaly detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9592–9600, 2019. 2, 5
[2] Paul Bergmann, Michael Fauser, David Sattlegger, and Carsten Steger. Uninformed students: Student-teacher anomaly detection with discriminative latent embeddings. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4183–4192, 2020. 5
[3] Paul Bergmann, Sindy Lowe, Michael Fauser, David Sattleg- ¨ ger, and Carsten Steger. Improving unsupervised defect segmentation by applying structural similarity to autoencoders. arXiv preprint arXiv:1807.02011, 2018. 1
[4] Niv Cohen and Yedid Hoshen. Sub-image anomaly detection with deep pyramid correspondences. arXiv preprint arXiv:2005.02357, 2020. 1, 2, 4
[5] Thomas Defard, Aleksandr Setkov, Angelique Loesch, and Romaric Audigier. Padim: a patch distribution modeling framework for anomaly detection and localization. In International Conference on Pattern Recognition, pages 475–489. Springer, 2021. 1, 2, 4, 7 [6] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009. 1
[7] Piotr Dollar, Mannat Singh, and Ross Girshick. Fast and ac- ´ curate model scaling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 924–932, 2021. 2
[8] Denis Gudovskiy, Shun Ishizaka, and Kazuki Kozuka. Cflow-ad: Real-time unsupervised anomaly detection with Figure 4. Visualization of results of anomaly localization for object classes in MVTec AD benchmark. localization via conditional normalizing flows. arXiv preprint arXiv:2107.12571, 2021. 6, 7
[9] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE international conference on computer vision, pages 1026–1034, 2015. 5
[10] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016. 7
[11] Chun-Liang Li, Kihyuk Sohn, Jinsung Yoon, and Tomas Pfister. Cutpaste: Self-supervised learning for anomaly detection and localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9664–9674, 2021. 1
[12] Tsung-Yi Lin, Piotr Dollar, Ross Girshick, Kaiming He, ´ Bharath Hariharan, and Serge Belongie. Feature pyramid networks for object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2117–2125, 2017. 5
[13] Rosanne Liu, Joel Lehman, Piero Molino, Felipe Petroski Such, Eric Frank, Alex Sergeev, and Jason Yosinski. An intriguing failing of convolutional neural networks and the coordconv solution. arXiv preprint arXiv:1807.03247, 2018. 5
[14] Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101, 2017. 5
[15] Sashank J Reddi, Satyen Kale, and Sanjiv Kumar. On the convergence of adam and beyond. arXiv preprint arXiv:1904.09237, 2019. 5
[16] Karsten Roth, Latha Pemula, Joaquin Zepeda, Bernhard Scholkopf, Thomas Brox, and Peter Gehler. Towards to- ¨ tal recall in industrial anomaly detection. arXiv preprint arXiv:2106.08265, 2021. 1, 2, 4, 6
[17] Marco Rudolph, Bastian Wandt, and Bodo Rosenhahn. Same same but differnet: Semi-supervised defect detection with normalizing flows. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 1907–1916, 2021. 7
[18] Lukas Ruff, Robert Vandermeulen, Nico Goernitz, Lucas Deecke, Shoaib Ahmed Siddiqui, Alexander Binder, Emmanuel Muller, and Marius Kloft. Deep one-class classifica- ¨ tion. In International conference on machine learning, pages 4393–4402. PMLR, 2018. 3
[19] Thomas Schlegl, Philipp Seebock, Sebastian M Waldstein, ¨ Ursula Schmidt-Erfurth, and Georg Langs. Unsupervised anomaly detection with generative adversarial networks to guide marker discovery. In International conference on information processing in medical imaging, pages 146–157. Springer, 2017. 1
[20] Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014. 7
[21] Jouwon Song, Kyeongbo Kong, Ye-In Park, Seong-Gyun Kim, and Suk-Ju Kang. Anoseg: Anomaly segmentation network using self-supervised learning. arXiv preprint arXiv:2110.03396, 2021. 1
[22] Mingxing Tan and Quoc Le. Efficientnet: Rethinking model scaling for convolutional neural networks. In International Conference on Machine Learning, pages 6105–6114. PMLR, 2019. 7
[23] Jihun Yi and Sungroh Yoon. Patch svdd: Patch-level svdd for anomaly detection and segmentation. In Proceedings of the Asian Conference on Computer Vision, 2020. 1, 3